历史文本的自然语言处理(一)
Reading #1 for the Digging the Past Group, course Language Technology: Research and Development
Reference:
Michael Piotrowski (2012) Natural Language Processing for Historical Texts, chapter 3: Spelling in Historical Texts
拼写差异和各种变体(variation)是历史文本中最明显的特征之一,也一直是自然语言处理中一项艰巨的任务。作者在本章中简要讨论了正字法(orthography)的重要性,并且从这一角度出发验证了历史文本与现代文本的区别。
3.1 自然语言处理中正字法所扮演的角色
提及正字法,我们首先想到的就是针对每个单词的正确拼写;然而,正字法与标点(punctuation)、缩写(abbreviation)、连字符(hyphenation)和词间分割(separation)都有联系。而后者因为和分词(tokenization)密切相关,因此也显得十分重要。分词是文本处理的第一步,因此对接下来的处理步骤也会产生影响。
包括信息检索(information retrieval)在内的自然语言处理工具通常假设需要处理的文本正字法规则保持一致。这是因为大部分的自然语言处理方法(technique)在某一时间都需要从词汇(lexical resources)中获取处理中所遇到的词形(word forms)信息,比如词性(part of speech)、格(case)和数(number);而且词形在获取信息这一环节至关重要。这一环节与词汇是手动构建(比如机器可读的传统字典)的还是从文本中自动抽取的无关。比如,WordNet(Fellbaum,1998)中包含了关于book一词的许多信息,但是针对boke或者booke的搜索都无法得到结果。
这一点同样适用于统计学的方法。统计学模型都基于“从训练集中(例如手工标注的语料库)获得的参数(parameter)同样也适用于其他数据”的假设。同样的,因为句子的表层形式(surface form)是自然语言处理的起点,单词的拼写也是重要的一项参数。统计学方法的优势是可以从稀疏(sparse)的训练集中做出推论。比如,一个词性标注器(POS tagger)可以预测,或者说,猜出一个新词的词性。但是这需要我们提供足量的已知词形的上下文相关的信息。未知的词形越多,标注器的可信度就越低。显而易见,如果输入文本的拼写与训练集中不同,未知词形的数量也会随之增加。除此之外,词缀(affixes),通常来说是后缀(suffixes)也能提供信息。以英语为例,如果一个生词以“-ion”结尾,那它很可能是一个名词。当然,隐患也随之而来:如果一个词缀的拼写方式不同,标注器并不能将各种变体联系起来。
信息检索同样严重依赖标准正字法。标准的信息检索工具假设文档的作者和检索人员在描述某一概念时使用的术语都相同,实际上,还要求拼写也严格一致。现代的搜索引擎已经能够处理指令(query)中的拼写错误,但是仅适用于文本集拼写风格一致(或者大体一致)的情况。查询扩展(query expansion)通过对指令进行可以处理构成指令的过程中潜在的形态学(morphological)、术语学(terminological)和词汇学(lexical)变化,但是针对这些变化(比如屈折变化(inflection)的模式)的规则需要提前定义。
3.2 拼写与历史文本
在拼写方面,历史文本有三个基本特征:一是拼写差异(spelling difference),即历史文本中的拼写与现代拼写可能有所不同。拼写的惯例(convention)随着时间推移有所变化,官方也时不时对正字法做出更改。最近一段时间最出名的几个例子在各自的语言群体(language community)中都引起了很大的争议:1996年德语正字法改革、1995荷兰语正字法改革和1990法语正字法改革。
二十世纪五十年代,中国的正字法改革中将汉字简化,而非使用拉丁字母进行书写;而有些语言,比如土耳其语、汉语或者蒙古语都在某个时间点采用了完全不同的书写方式,这种变化大到不能仅仅把它称为“正字法改革”。1 在过往的文本中使用的拼写和拼写惯例和今日也有所不同:在涵盖时期比较久的历时语料库(diachronic historcial corpus)中通常能发现不少的拼写差异。
1 1928年,土耳其的书写系统从阿拉伯字母转化为拉丁字母。韩语文字谚文(Hangul)在15世纪被创造出来,但是从汉字(Hanja)到谚文的转变一直持续到20世纪早期,而现在谚文几乎完全取代了汉字。传统的蒙古语书写系统与阿拉伯字母有一定关系,但是是竖写,二十世纪三十年代,拉丁字母被引入,但最终被西里尔(Cyrillic)字母取代。
第二,一个或者多个国家内的标准正字法是相对来说比较新兴的产物。比如德语正字法1901年才出现,葡萄牙语则是1911年。在那之前,拼写虽然不是完全随性而为,但是既然没有标准,也就不存在什么“正确拼写”的概念。在当时起到正字法作用的是不同的拼写“派别”,或者说是书面方言(written dialects)和通常反映当地读音的一系列被人接受的拼写。这就意味着,在过去哪怕是同一时代下的文本可能都会有很大的不同。一个作者在一篇文章中使用很多种拼写来表示同一个单词也很常见。这种现象我们可以称之为拼写变体(spelling variance)。
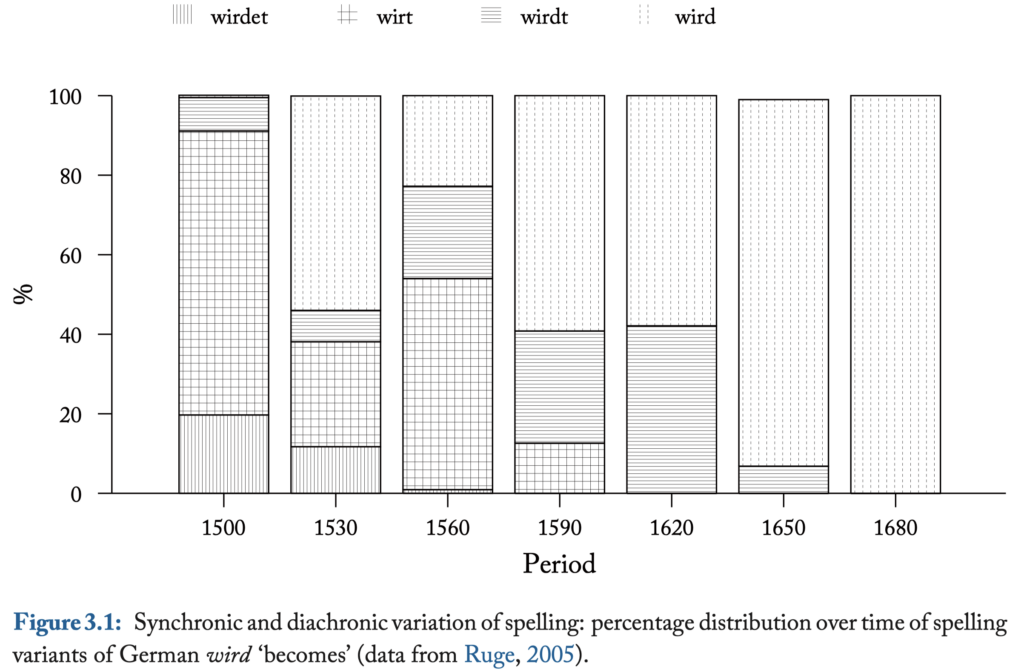
从语言学的角度来说,这两个拼写上的问题分别与“历时”和“共时”(synchronic)有关。图3-1展现了在一个历时语料库中德语单词“wird”(“成为”,第三人称单数,现在时,陈述语气)的不同拼写出现次数的百分比,从而对这两个问题作出一定的解释。我们可以发现,在1530年左右,四种拼写同时存在,这些是共时的拼写变体。从时间的坐标轴上观察得知,最终“wird”被逐渐接受,这就是历时的变化。2
2 可能会有认为“wirdet”实际上反映了另外一种读音,因此并不能算作是一种拼写变体。实际上,Ruge发现在中古高地德语(Middle High German)到现代高地德语(New High German)的过渡时期,词形显式(explict)的“wirdet“和隐(contracted)的“wird”还处在竞争中;然而后者在中古高地德语中就已经出现(非重读的元音已经丢失)。Wright写到:“在字母e前面如果没有鼻音,在口头用语中有时就会被省去,以字母t来代替,比如,wirst和wirt以前分别是wirdes(t)和wirdet。”考虑到这一明显的倾向,至少可以认为一些显式的拼写是在拟古(archaism),也就是说,有的人写“wirdet”但是却读“wird”,这一点可以和英语中以-ed结尾的词作类比。为了方便后续讨论,我们认为可以将这些形式都看作是拼写变体。
(未完待续)
This passage is a translation attempt of the original text, for learning purposes only and is open to any idea exchange and translation modification. All rights reserved.
本文是对英文原文的试译,仅用于学习用途;水平有限,欢迎交流;未经允许,不得转载。
Leave a Reply